Linux内存压缩浅析之原理
1. 技术背景
相信对于搞技术的人来说,压缩这个词并不陌生,一想到这个词,我们首先想到的是压缩可以降低占用空间,使同样的空间可以存放更多的东西,类似于我们平时常用的文件压缩。 顾名思义,内存压缩就是压缩内存,节省内存空间。
你可能会说换个内存大的不就行了吗?但是但内存无论多大,总是会有不够用的时候,或者说我们总是想在尽量低的成本控制下,达到系统最优,这个时候还是有必要引入诸如内存压缩的功能来优化系统内存占用。当系统内存紧张的时候,会将文件页丢弃或回写回磁盘(如果是脏页),还可能会触发LMK杀进程进行内存回收。这些被回收的内存如果再次使用都需要重新从磁盘读取,而这个过程涉及到较多的IO操作。就目前的技术而言,IO的速度远远慢于这RAM操作速度。因此,如果频繁地做IO操作,不仅影响flash使用寿命,还严重影响系统性能。内存压缩是一种让IO过程平滑过渡的做法, 即尽量减少由于内存紧张导致的IO,提升性能。2. 主流内存压缩技术
目前linux内核主流的内存压缩技术主要有3种:zSwap, zRAM, zCache。下面我们依次对几种方式进行一个简要的说明
2.1 zSwap
zSwap是在memory与flash之间的一层“cache”,当内存需要swap出去磁盘的时候,先通过压缩放到zSwap中去,zSwap空间按需增长。达到一定程度后则会按照LRU的顺序(前提是使用的内存分配方法需要支持LRU)将就最旧的page解压写入磁盘swap device,之后将当前的page压缩写入zSwap。
zswap本身存在一些缺陷或问题:
1) 如果开启当zswap满交换出backing store的功能, 由于需要将zswap里的内存按LRU顺序解压再swap out, 这就要求内存分配器支持LRU功能。
2) 如果不开启当zswap满交换出backing store的功能, 和zRam是类似的。
2.2 zRram
zRram即压缩的内存, 使用内存模拟block device的做法。实际不会写到块设备中去,只会压缩后写到模拟的块设备中,其实也就是还是在RAM中,只是通过压缩了。由于压缩和解压缩的速度远比读写IO好,因此在移动终端设备广泛被应用。zRam是基于RAM的block device, 一般swap priority会比较高。只有当其满,系统才会考虑其他的swap devices。当然这个优先级用户可以配置。
zRram本身存在一些缺陷或问题:
1) zRam大小是可灵活配置的, 那是不是配置越大越好呢? 如果不是,配置多大是最合适的呢?
2) 使用zRam可能会在低内存场景由于频繁的内存压缩导致kswapd进程占CPU高, 怎样改善?
3) 增大了zRam配置,对系统内存碎片是否有影响?
要利用好zRam功能, 并不是简单地配置了就OK了, 还需要对各种场景和问题都做好处理, 才能发挥最优的效果。
2.3 zCache
zCache是oracle提出的一种实现文件页压缩技术,也是memory与block dev之间的一层“cache”,与zswap比较接近,但zcache目前压缩的是文件页,而zSwap和zRAM压缩是匿名页。
zcache本身存在一些缺陷或问题:
1) 有些文件页可能本身是压缩的内容, 这时可能无法再进行压缩了
2) zCache目前无法使用zsmalloc, 如果使用zbud,压缩率较低
3) 使用的zbud/z3fold分配的内存是不可移动的, 需要关注内存碎片问题
3.内存压缩主流的内存分配器
3.1 Zsmalloc
zsmalloc是为ZRAM设计的一种内存分配器。内核已经有slub了, 为什么还需要zsmalloc内存分配器?这是由内存压缩的场景和特点决定的。zsmalloc内存分配器期望在低内存的场景也能很好地工作,事实上,当需要压缩内存进行zsmalloc内存分配时,内存一般都比较紧张且内存碎片都比较严重了。如果使用slub分配, 很可能由于高阶内存分配不到而失败。另外,slub也可能导致内存碎片浪费比较严重,最坏情况下,当对象大小略大于PAGE_SIZE/2时,每个内存页接近一半的内存将被浪费。
实测发现,anon pages的平均压缩比大约在1:3左右,所以compressed anon page size很多在1.2K左右。如果是Slub,为了分配大量1.2K的内存,可能内存浪费严重。zsmalloc分配器尝试将多个相同大小的对象存放在组合页(称为zspage)中,这个组合页不要求物理连续,从而提高内存的使用率。

需要注意的是, 当前zsmalloc不支持LRU功能, 旧版本内核分配的不可移动的页, 对内存碎片影响严重, 但最新版本内核已经是支持分配可移动类型内存了。
3.2 Zbud
zbud是一个专门为存储压缩page而设计的内存分配器。用于将2个objects存到1个单独的page中。zbud是可以支持LRU的, 但分配的内存是不可移动的。
3.3 Z3fold
z3fold是一个较新的内存分配器, 与zbud不同的是, 将3个objects存到1个单独的page中,也就是zbud内存利用率极限是1:2, z3fold极限是1:3。同样z3fold是可以支持LRU的, 但分配的内存是不可移动的。
4.内存压缩技术与内存分配器组合对比分析
结合上面zSwap / zRam /zCache的介绍, 与zsmalloc/zbud/z3fold分别怎样组合最合适呢?
下面总结了一下, 具体原因可以看上面介绍的时候各类型的特点。

5.zRAM技术原理
本文重点介绍zRam内存压缩技术,它是目前移动终端广泛使用的内存压缩技术。
5.1 软件框架
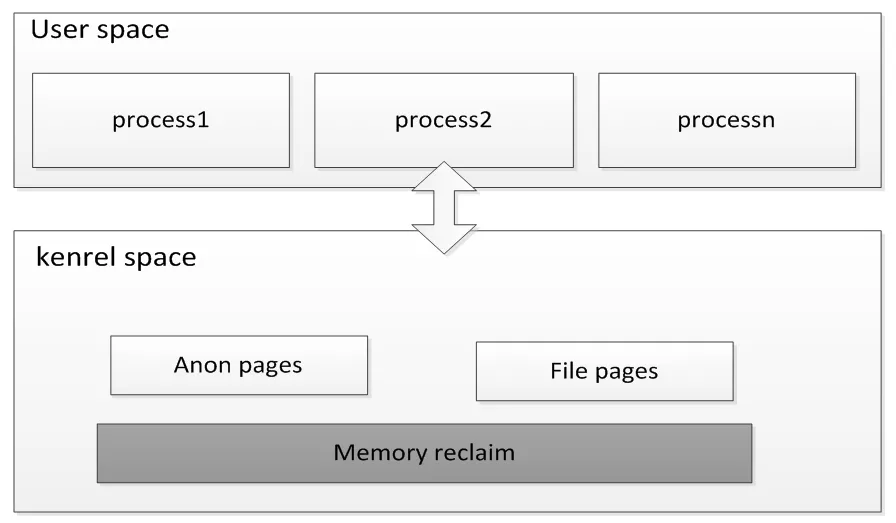
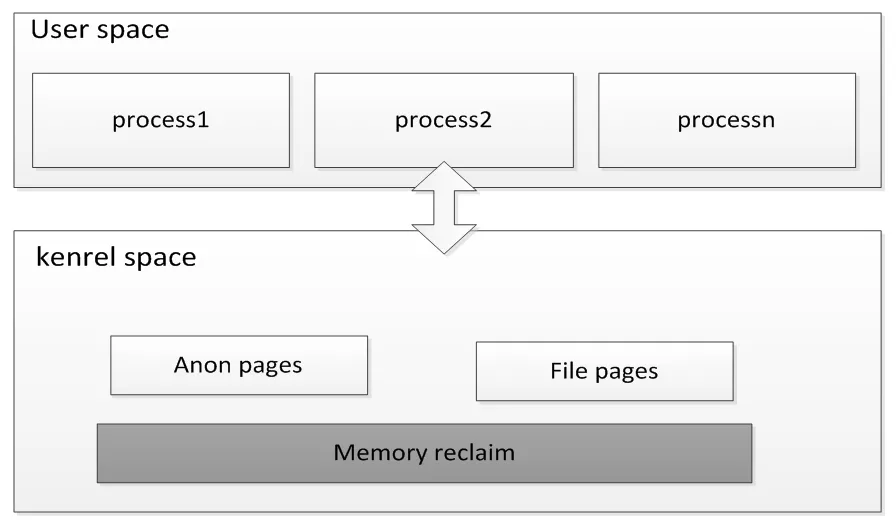
下图展示了内存管理大体的框架, 内存压缩技术处于内存回收memory reclaim部分中。
再具体到zRam, 它的软件架构可以分为3部分, 分别是数据流操作,内存压缩算法 ,zram驱动。

数据流操作:提供串行或者并行的压缩和解压操作。
内存压缩算法:每种压缩算法提供压缩和解压缩的具体实现回调接口供数据操作调用。
Zram驱动:创建一个基于ram的块设备, 并提供IO请求处理接口。
5.2 实现原理
Zram内存压缩技术本质上就是以时间换空间。通过CPU压缩、解压缩的开销换取更大的可用内存空间。
我们主要描述清楚下面这2个问题:
1) 什么时候会进行内存压缩?
2) 进行内存压缩/解压缩的流程是怎样的?
进行内存压缩的时机:
1) Kswapd场景:kswapd是内核内存回收线程, 当内存watermark低于low水线时会被唤醒工作, 其到内存watermark不小于high水线。
2) Direct reclaim场景:内存分配过程进入slowpath, 进行直接行内存回收。

下面是基于4.4内核理出的内存压缩、解压缩流程。
内存回收过程路径进行内存压缩。会将非活跃链表的页进行shrink, 如果是匿名页会进行pageout, 由此进行内存压缩存放到ZRAM中, 调用路径如下:

在匿名页换出到swap设备后, 访问页时, 产生页访问错误, 当发现“页表项不为空, 但页不在内存中”, 该页就是已换到swap区中,由此会开始将该页从swap区中重新读取, 如果是ZRAM, 则是解压缩的过程。调用路径如下:

5.3 内存压缩算法
目前比较主流的内存算法主要为LZ0, LZ4, ZSTD等。下面截取了几种算法在x86机器上的表现。各算法有各自特点, 有以压缩率高的, 有压缩/解压快的等, 具体要结合需求场景选择使用。
6.zRAM技术应用
本节描述一下在使用ZRAM常遇到的一些使用或配置,调试的方法。
6.1 如何配置开启zRAM
1) 配置内存压缩算法
下面例子配置压缩算法为lz4
echo lz4 > /sys/block/zram0/comp_algorithm2) 配置ZRAM大小
下面例子配置zram大小为2GB
echo 2147483648 > /sys/block/zram0/disksize
3) 使能zram
mkswap /dev/zram0
swapon /dev/zram0
4)zram 块设备个数设定
如果是编译为内核模块,那么可以在内核模块加载的时候,添加参数:insmod zram.ko num_devices=4
也可直接修改内核源代码:
代码地址为:/drivers/block/zram/zram_drv.c
/* Module params (documentation at end) */
static unsigned int num_devices = 1;
修改num_devices为你想要的zram个数即可
5)压缩流的最大个数设定
这个是 3.15 版本及以后的 kernel 新加入的功能,3.15 版本之前的 zram 压缩都是使用一个压缩流(缓存 buffer 和算法私有部分)实现,每个写(压缩)操作都会独享压缩流,但是单压缩流如果出现数据奔溃或者卡住的现象,所有的写(压缩)操作将一直处于等待状态,这样效率非常低;而多压缩流的架构会让写(压缩)操作可以并行去执行,大大提高了压缩的效率和稳定性。
查看压缩流个数:默认是1,可以直接向proc文件写入,也可以直接更改代码方式来改变默认压缩流个数
cat /sys/block/zram0/max_comp_streams
设定压缩流个数:
echo 3 > /sys/block/zram0/max_comp_streams
6)其他参数
| Name | Access | Description |
|---|---|---|
| disksize | RW | 显示和设置该块设备的内存大小 |
| initstate | RO | 显示设备的初始化状态 |
| reset | WO | 重置设备 |
| num_reads | RO | 读数据的个数 |
| failed_reads | RO | 读数据失败的个数 |
| num_write | RO | 写数据的个数 |
| failed_writes | RO | 写数据失败的个数 |
| invalid_io | RO | 非页面大小对齐的I/O请求的个数 |
| max_comp_streams | RW | 最大可能同时执行压缩操作的个数 |
| comp_algorithm | RW | 显示和设置压缩算法 |
| notify_free | RO | 空闲内存的通知个数 |
| zero_pages | RO | 写入该块设备的全为的页面的个数 |
| orig_data_size | RO | 保存在该块设备中没有被压缩的数据的大小 |
| compr_data_size | RO | 保存在该块设备中已被压缩的数据的大小 |
| mem_used_total | RO | 分配给该块设备的总内存大小 |
| mem_used_max | RW | 该块设备已用的内存大小,可以写 1 重置这个计数参数到当前真实的统计值 |
| mem_limit | RW | zram 可以用来保存压缩数据的最大内存 |
| pages_compacted | RO | 在压缩过程中可用的空闲页面的个数 |
| compact | WO | 触发内存压缩 |
6.2 swappiness含义简述
swappiness参数是内核倾向于回收匿名页到swap(使用的ZRAM就是swap设备)的积极程度, 原生内核范围是0~100, 参数值越大, 表示回收匿名页到swap的比例就越大。如果配置为0, 表示仅回收文件页,不回收匿名页。默认值为60。可以通过节点“/proc/sys/vm/swappiness”配置。
6.3 zRam相关的技术指标
1) ZRAM大小及剩余空间
Proc/meminfo中可以查看相关信息
SwapTotal:swap总大小, 如果配置为ZRAM, 这里就是ZRAM总大小
SwapFree:swap剩余大小, 如果配置为ZRAM, 这里就是ZRAM剩余大小
当然, 节点 /sys/block/zram0/disksize是最直接的。
2) ZRAM压缩率
/sys/block/zram
orig_data_size:压缩前数据大小, 单位为bytes
compr_data_size :压缩后数据大小, 单位为bytes
3) 换出/换入swap区的总量, proc/vmstat中中有相关信息
pswpin:换入总量, 单位为page
pswout:换出总量, 单位为page
6.4 zRam相关优化
上面提到zRam的一些缺陷, 怎么去改善呢?
1) zRam大小是可灵活配置的, 那是不是配置越大越好呢? 如果不是配置多大是最合适的呢?
zRam大小的配置比较灵活, 如果zRam配置过大, 后台缓存了应用过多, 这也是有可能会影响前台应用使用的流畅度。另外, zRam配置越大, 也需要关注系统的内存碎片化情。因此zRam并不是配置越大越好,具体的大小需要根据内存总大小及系统负载情况考虑及实测而定。
2) 使用zRam,可能会存在低内存场景由于频繁的内存压缩导致kswapd进程占CPU高, 怎样改善?
zRam本质就是以时间换空间, 在低内存的情况下, 肯定会比较频繁地回收内存, 这时kswapd进程是比较活跃的, 再加上通过压缩内存, 会更加消耗CPU资源。改善这种情况方法也比较多, 比如, 可以使用更优的压缩算法, 区别使用场景, 后台不影响用户使用的场景异步进行深度内存压缩, 与用户体验相关的场景同步适当减少内存压缩, 通过增加文件页的回收比例加快内存回收等等。
3) 增大了zRam配置,对系统内存碎片是否有影响?
使用zRam是有可能导致系统内存碎片变得更严重的, 特别是zsmalloc分配不支持可移动内存类型的时候。新版的内核zsmalloc已经支持可移动类型分配的, 但由于增大了zRam,结合android手机的使用特点, 仍然会有可能导致系统内存碎片较严重的情况,因些内存碎片问题也是需要重点关注的。解决系统内存碎片的方法也比较多, 可以结合具体的原因及场景进行优化。
6.5 zRam 块设备
zram 本质是就是一个块设备,所以下面先简单介绍一下块设备的一些基础知识,块设备相关的原理和技术细节,我后续会专门列举一个IO的专题来进行讲解,这里仅仅列举一些基础的知识。
6.5.1 块设备的基本概念
-
块设备(block device)
块设备是一种具有一定结构的随机存取设备,对这种设备的读写是按块进行的,使用缓冲区来存放暂时的数据,待条件成熟后,从缓存一次性写入设备或者从设备一次性读到缓冲区。
-
扇区 (Sectors)
块设备中最小的可寻址单元,大小一般都是 2 的整数倍,最常见的是 512 字节。
-
块 (Blocks)
块是文件系统的一种抽象,只能基于块来访问文件系统,块必须是扇区大小的 2 的整数倍,并且要小于一个内存页面的大小,所以通常块的大小是 512 字节、1 KB 或 4 KB 。
-
段 (Segments)
由若干个相邻的块组成,是 Linux 内存管理机制中一个内存页或者内存页的一部分。
-
页面 (Page)
物理页是 Linux 内存管理的基本单位,一般一个页面是 4KB 或者 64 KB。
上述几个基本概念的关系图:

6.5.2 块设备驱动总体架构图

6.5.3. 相关数据结构
-
block_device
描述一个分区或整个磁盘对内核的一个块设备实例。
-
gendisk
描述一个通用硬盘(generic hard disk)对象。
-
hd_struct
描述分区应有的分区信息。
-
bio
描述块数据传送时怎样完成填充或读取块给 driver,既描述了磁盘的位置,又描述了内存的位置。
-
bio_vec
描述 bio 中的每个段。
-
request
描述向内核请求一个列表准备做队列处理。
-
request_queue
描述内核申请 request 资源建立请求链表并填写 bio 形成队列。
6.5.4. zram 架构
zram 从架构上可以分为三部分:
-
驱动部分
该部分创建了一个块设备,然后提供了处理 IO 请求的接口;
-
数据流操作部分
该部分主要提供串行或者并行的压缩和解压操作;
-
解压缩算法部分
该部分主要是一个个压缩和解压算法,每个算法都提供统一的压缩和解压接口给数据流操作部分调用。
6.5.5. zram 驱动部分代码分析
-
zram_init
首先调用 register_blkdev 注册块设备驱动到内核中,然后再根据 num_devices 调用 create_device 来创建相应个数的块设备, 这里默认是创建一个块设备。
-
create_device
对于 flash、 RAM 等完全随机访问的非机械设备,并不需要进行复杂的 I/O 调度,所以这里直接调用 blk_alloc_queue 分配一个 “请求队列”,然后使用 blk_queue_make_request 函数绑定分配好的 “请求队列” 和 “请求处理”函数 zram_make_request。接着初始化块设备的操作函数集 zram_devops 及设备容量、名字、队列等其他属性,最后调用 add_disk 将该块设备真正添加到内核中。
-
disksize_store
zram 使用了 Zsmalloc 分配器来管理它的内存空间,Zsmalloc 分配器尝试将多个相同大小的对象存放在组合页(称为 zspage)中,这个组合页不要求物理连续,从而提高内存的使用率。
首先会根据 zram 的内存中页面的个数,创建相应个数的 zram table,每个 zram table 都对应一个页面;然后会调用 zs_create_pool 创建一个 zsmalloc 的内存池,以后所有的页面申请和释放都是通过 zs_malloc 和 zs_free 来分配和释放相对应的对象。
-
zram_make_request
在整个块设备的 I/O 操作中,贯穿于始终的就是“请求”,块设备的 I/O 操作会排队和整合。块设备驱动的任务就是处理请求,对请求的排队和整合则是由 I/O 调度算法解决,因此,zram 块设备驱动的核心这个请求处理函数,所有的 zram I/O 请求都是通过这个请求处理函数来处理的。
首先它判断这个 I/O 请求是否是有效的,即检测请求是否在 zram 逻辑块的范围以内,且是否对齐。然后调用 __zram_make_request 遍历 bio 中的每个段 bio_vec,根据 bio 的传输方向选择执行写 (zram_bvec_write) 或者读 (zram_bvec_read) 操作。
-
zram_bvec_write
在写数据之前,首先使用 GFP_NOIO 标志创建一个不允许任何 I/O 初始化的页面,然后将 zram_data 对应的数据先解压出来放到该创建的页面中。接着去调用 zcomp_strm_find 找到一个压缩操作流,如果是单压缩流,则实际调用的是 zcomp_strm_single_find,如果是多压缩流,则实际调用的是 zcomp_strm_multi_find。
然后,将段 bio_vec 中的页面临时映射到高端地址,并将高端地址空间页面的内容复制到已保存好 zram_data 压缩后的数据的页面。调用 zs_malloc 申请一个 zram table,使 zcomp_compress 压缩内容并将压缩后的内容存放到新申请的 zram table。最后调用 zram_free_page 删除旧内容所占用的 zram table。
zcomp_decompress 会根据 struct zcomp_backend 初始化时设定的压缩算法来调用相应的解压接口,lzo 压缩算法的解压接口是 lzo_compress ,而 lz4 压缩算法的解压接口是 zcomp_lz4_compress ,该接口还调用了压缩操作流,以此执行串行或者并行写操作。
-
zram_bvec_read
读操作首先将段 bio_vec 中的页面临时映射到高端地址,然后再调用 zram_decompress_page 将 zram_meta 所对应的数据解压到这块映射的高端内存空间,解压的接口是 zcomp_decompress,它会根据 struct zcomp_backend 初始化时设定的压缩算法来调用相应的解压接口,lzo 压缩算法的解压接口是 lzo_decompress ,而 lz4 压缩算法的解压接口是 zcomp_lz4_decompress 。
6.5.6. 数据流操作部分代码分析
-
zcomp_create
若最大可能同时执行压缩操作的个数来调用为一,则调用 zcomp_strm_single_create 来创建一个压缩流,而若最大可能同时执行压缩操作的个数来调用大于一,则调用 zcomp_strm_multi_create 先创建一个压缩流,然后创建一个压缩流链表,并将创建好的压缩流加到压缩流链表中,后面再根据需求来动态创建更多的压缩流。
-
zcomp_strm_multi_find
单压缩流非常简单,如果前一个压缩操作已经持有 strm_lock 锁,那么下一个压缩操作必须等待前一个压缩操作调用 zcomp_strm_single_release 释放该锁才可以接着执行。
-
zcomp_strm_multi_find
多压缩流就相对复杂一点,只要压缩流的个数没有达到最大的个数,那么压缩操作都可以分配到一个压缩流,并会加到压缩流链表中,当压缩流的个数达到最大限制之后,那么下一个压缩操作只能睡眠等待链表中有空闲的压缩流出现。
参考资料:
[1] https://github.com/lz4/lz4
[2] https://www.kernel.org/doc/Documentation/blockdev/zram.txt
[3] https://www.kernel.org/doc/Documentation/vm/zswap.txt